Memstate is a complete redesign of OrigoDB with major improvements in key areas such as performance, availability, licensing, cross-platform, docker and cloud support.
Please visit Memstate on Github for more information!
OrigoDB is an in-memory object graph database with an ACID transactional engine at it’s heart. Data modeling, commands and queries are written procedurally using any NET language or functionally using LINQ.
The engine, many plugins and data models are all open source and hosted on github. OrigoDB Server, offered commercially, is a standalone server with enterprise features like high availability, replication, monitoring and operations.
The initial design goals were focused on rapid development, testability, simplicity, correctness, modularity, flexibility and extensibility. Performance was never a primary goal but running in-memory with memory optimized data structures outperforms any disk oriented system. The primary use case for OrigoDB is handling complex and heavy OLTP workloads in enterprise software.
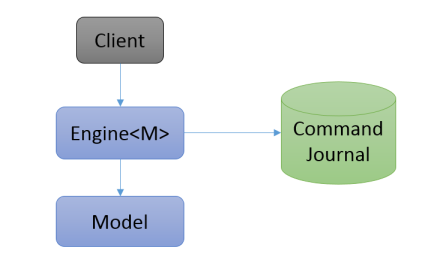
The core component is the Engine. The engine is 100% ACID, runs in-process and hosts a user defined data model. The data model can be domain specific or generic and is defined using plain old NET types. Persistence is based on snapshots and write-ahead command logging to the underlying storage.
IFormatter implementations. Binary, JSON, ProtoBuf, etcRead more in the docs on Extensibility
 ORIGO
ORIGO