Memstate is a complete redesign of OrigoDB with major improvements in key areas such as performance, availability, licensing, cross-platform, docker and cloud support.
Please visit Memstate on Github for more information!
The other day I attended a meetup hosted by Speedment, an exciting start up leveraging the power of in-memory in a way similar to OrigoDB. It was a great evening that started off with free beer and pizza. Presentations by Hazelcast CTO Talip Ozturk and Speedment CTO Per-Åke Minborg followed. I made some new friends, got some new ideas and inspiration for future OrigoDB directions. Oh, and did I mention free beer and pizza?
In this blog post I’ll present the Speedment core concept, why it’s a very powerful idea and how you can do something similar using OrigoDB.
Reading from memory is 6 orders of magnitude faster than random disk reads. Both Speedment and Origo benefit by holding large portions of data in optimized object graph structures in RAM. Hundreds of thousands or even millions of queries per second on a single commodity server is not uncommon. Whereas Origo takes an all-in approach, Speedment is architected to integrate with existing relational databases and legacy applications. A transactionally consistent subset of the relational data lives in RAM in the application process. After an initial pull population, database triggers are used to capture changes and keep the in-memory data in sync. Some of the strengths of this approach are:
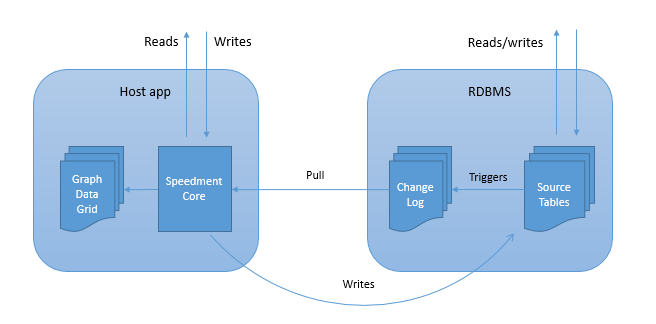
Reads and writes at the application are managed by the Speedment Core. Writes are routed through the RDBMS and eventually propogate back to the application. Changes are fetched at a given interval and applied to the in-memory graph.
The Speedment UI is a graphical tool used to connect to the RDBMS and generate java code from the metadata. Entities, strongly typed collections, relationships, keys and indexes are mapped. It also generates DDL statements for the triggers and change log.
An OrigoDB model is usually hand-crafted and domain specific with no coupling to an existing relational model. Applying the Speedment concept we would monitor changes in an RDBMS using triggers (or the CDC feature of MSSQL) and update the in-memory model by mapping change events to OrigoDB commands.
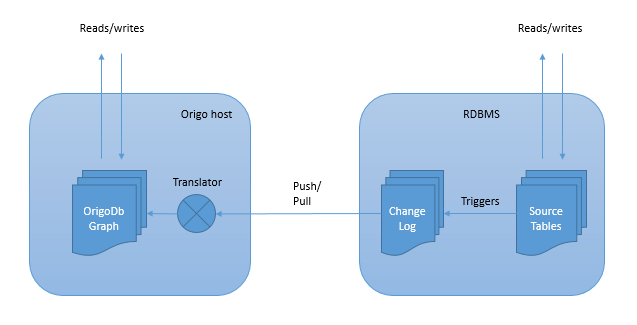
This is a fully viable approach but requires a deal of manual coding. Can we go all in with the Speedment way and generate an in-memory model from an existing RDBMS? Judging by the source, I think it would be fairly easy to integrate with the Speedment UI to generate C# code instead of java. An alternative which integrates nicely with Visual Studio, would be T4 template for use with the ADO.NET Entity Data Model.
 ORIGO
ORIGO